О прохождении курса Реальный Директ

О впечатлениях
Раньше я настраивал Директ, пользуясь отрывочными знаниями из хелпа Яндекса, статей оптимизаторов и видео с YouTube. Этого на первом этапе хватало, чтобы запуститься хоть как-то. Однако со временем стало ясно, что для более серьезных результатов нужны более основательные знания. Нужна основа, которая бы «цементировала» все остальные сведения.
В итоге я купил и удаленно прошел курс от Бизнес Молодости — Реальный Директ. Сначала курс проводился в живую, затем организаторы БМ переместили видео уроков вместе с полезными материалами (чек-листы, промокоды, скринкасты, ссылки на программы и прочее) в свою онлайн платформу и открыли платный доступ всем желающим. Многое из всего пройденного материала я еще не успел использовать на практике.
Что понравилось
- Интересная подача материала с БМ-ими фишками. Учат не думать галочками, а прежде всего предпринимательской выгодой;
- Одиозные спикеры: Илья Исерсон из MOAB, Леонид Гроховский из ТопЭксперт, Алексей Довжиков из eLama и другие.
Что не понравилось
- Большие куски видео, не заточенные под онлайн-обучение. Вначале это был просто оффлайн-курс, записанный на видео. Затем его упаковали, добавили материалов и стали «рубить бабло», продавая как онлайн;
- Остановленная поддержка курса. Создатели обещали делать апдейты, но никаких изменений нет. А Яндекс уже давно убежал вперед. На многих онлайн-площадках, например на Udemy, при покупке курса он бесплатно обновляется.
Мой алгоритм работы с семантикой
Так как БМ основной упор делает на семантику, в данном посте расскажу о моем подходе в работе с ней.
Ниже конспекты занятий:
- Занятие 1 — Оценка своего уровня и постановка цели;
- Занятие 2 — Конкурентная разведка;
- Занятие 3 — Сбор базовой семантики;
- Занятие 4 — Парсинг, минусация, искусственная семантика;
- Занятие 5 — Структура кампаний, написание объявлений, подключение Яндекс Метрики;
- Занятие 6 — Настройки кампании. Модерация;
- Занятие 7 — Автоматизация и подключение бид-менеджера;
- Занятие 8 — Великая РСЯ;
- Занятие 9 — Менеджмент, работа с директологом;
- Занятие 10 — Аналитика, докрутка.
Для примера возьму кейс по продаже металлочерепицы.
БМ рекомендует создавать семантику на основе майнд-карт. Отдельные ветки которых служат для создания базовых ключевиков. Базовый ключевик — это слово (или словосочетание) для дальнейшего распарсивания. Например, просто «черепица» базовым ключевиком считаться не будет, так как ее видов бывает множество. А вот «металлочерепица» или «металлическая черепица» в самый раз.
В итоге ветки таких ключевиков создаются мозговым штурмом и собиранием ключей с помощью расширения для браузера Yandex Wordstat Assistant. Затем ключи перемножаются и распарсиваются.
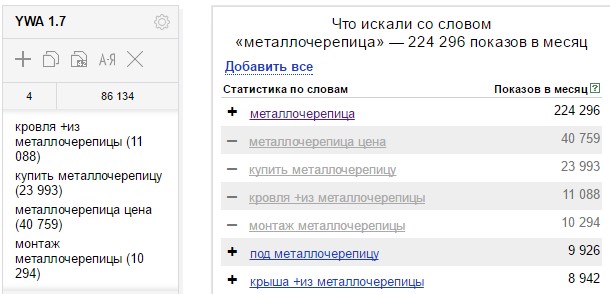
Я попробовал данный подход, он мне показался чересчур долгим и неэффективным. Карты получались большими и неудобными в последующей работе.
Пример моей майнд-карты из XMind. Она не кликабельна, просто чтобы показать масштаб работы.
Гораздо эффективнее и быстрее идти от обратного. Взять большой массив данных и разбить его на нужные семантические сегменты.
Всем прошедшим курс Реальный Директ от БМ был предоставлен трехмесячный бесплатный доступ в базу ключевых слов MOAB по подписке Suggest Pro.
Взяв на вооружение метод «верхней сущности» я задал запрос «металлочерепица» для наибольшего целевого охвата. Просто слово черепица дало бы неоправданно много мусора. Хотя, разумеется, затем нужно будет заняться этим запросом тоже. На данном этапе необходимо соблюсти принцип поэтапного развития – сначала делаем хоть как-то, потом повышаем эффективность. Более конкретное «металлочерепица Монтеррей» (именно только изделия данного профиля мы продаем) намного сузило бы охват.
Как мы видим на скриншоте, выборка дала нам более 120 тыс. ключевиков.

Основная проблема — много гео-мусора и названий фирм. Это будет замыливать глаз и усложнять работу.

Хотя и данная проблема легко решается Анализом групп в КейКоллекторе, где можно быстро пройтись по списку, добавить ненужное в список стоп-слов, а затем удалить. Но с удалением строк могут пропасть также уникальные редкие фразы. Поэтому по возможности нужно «щадяще» пакетно очистить массив от мусора, предварительно его собрав. Для пакетного удаления отдельных словосочетаний в строках нужны 1) программа 2) сам список слов.
Программу порекомендовал знакомый программист, который делал мне SynWord. В работе с любым новым софтом желательно всегда сохранять гайд, чтобы потом 1) можно было вспомнить все самому 2) переслать исполнителю.
Пример мини-гайда по программе Advanced Find and Replace 4.
Собирать слова руками самому долго и непродуктивно. А все ,что может быть автоматизировано, должно быть автоматизировано. Поэтому я быстро составил ТЗ знакомому фрилансеру, высылал файл и через пару дней получил более 2 тысяч мусорных слов. Пример ТЗ фрилансеру.
В итоге получаем файл от MOAB, очищенный от очевидного мусора. Гео-добавки на данной этапе мусор очевидный, так как мы будем продвигаться по конкретному региону и, распарсивая ключи дальше, получим все местные географические привязки и названия фирм конкурентов.
Загружаем файл в КейКоллектор. Делаем анализ неявных дублей и умную групповую отметку. Это позволит «схлопнуть» фразы типа: «металлочерепица цена» и «цена металлочерепица». Группировать и удалять можно и с учетом частотности.
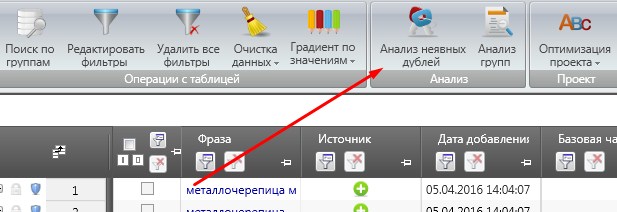
Далее полученный массив ключевых фраз я открываю в Анализе групп и прохожу каждое слово (группу слов), раскидывая их по отдельным спискам стоп-слов.
Таким образом мы собственно и создаем ветки нужной нам майнд-карты. Только уже из статистически достоверного огромного массива реально вводимых ключевиков и уже в удобном формате в КейКоллекторе, который позволяет отмечать слова из списка и раскидывать их отдельно по папкам внутри.

Таким образом, мы не только находим все даже редкие слова, мы ничего не выкидываем и не удаляем. Каждая группа слов в своей папке. И мы можем «нарезать» массив, дробя его этими списками как нам нужно. Хотим быстро запускаться — сразу отсекаем и перемещаем отдельно «горячие» (цена, купить, стоимость, под ключ и т.п.). Внутри уже этого массива можно отделять фразы по спискам «действие» (монтаж), «нищеброды» (бу, некондиция, дешево) и так далее.
Одновременно так можно и делать кластеризацию для дальнейшего SEO. Понятно, что семантика для Директа и для SEO — разные вещи. И для SEO нужно будет отдельно снимать частотность по региону продвижения. Для Директа берем всю семантику, чем больше охват, тем лучше.
Данные группы стоп-слов нам пригодятся и в дальнейшей работе со смежными тематиками. Их можно отдельно сохранять, скажем, в Google Docs и дополнять.
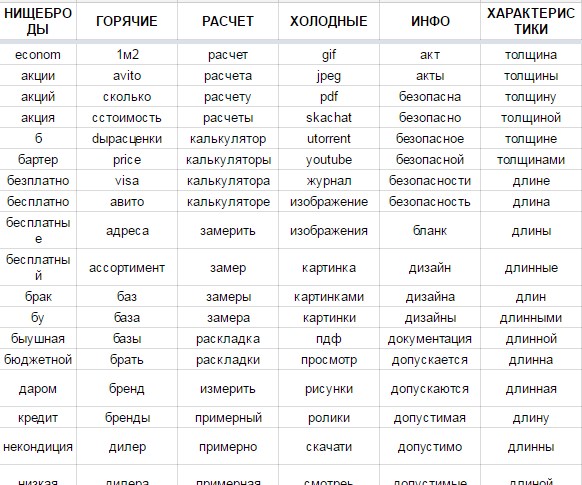
Далее для особо «замороченных» можно на основании полученных списков отдельно обрабатывать слова для использования их в создании искусственной семантики.
Пример слов, связанных с установкой металлочерепицы:

Далее можно делать формулы генерации для создания нужных нам фраз из отдельных слов:

Подобные формулы можно добавлять прямо внутрь группы объявлений (в круглых скобках), но Яндекс накладывает ограничение на максимальное количество фраз в группе:
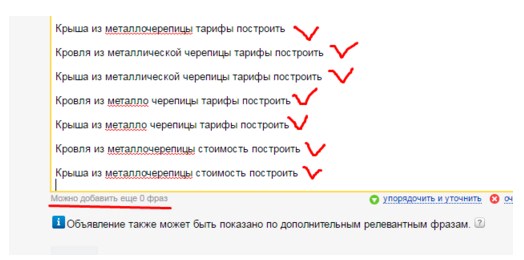
Дальше можно распарсивать собранные ключи вглубь, в том числе подсказками, отдельно уже собирая местные гео-привязки, бренды здешних конкурентов и прочее. В общем локализовывать кампанию и приступать к созданию объявлений.
Для SEO снимать частотность по своему региону, делать более «тонкую» кластеризацию (в КейКоллекторе или других программах, например, МегаЛемме, делать задание копирайтерам и размещать контент на сайте.
Комментарии